Handy Python packages for job title classification model

Introduction
Handling vast amounts of workforce data can often be a daunting and time-consuming task, particularly when it comes to standardizing job titles from employee records or candidate resumes. A significant challenge in this process is the diversity of job titles used for similar roles. For instance, while one individual might refer to their role as 'Delivery Lead,' another might call themselves a 'Solution Architect,' even though both positions essentially align with a software engineering manager’s responsibilities.
In my recent project researching the career paths of Chief Data Officers (CDOs) in the UK, I encountered around 3,000 unique job titles from approximately 500 professionals. To extract meaningful insights into the career trajectories leading to the CDO role, it was crucial to categorize these titles into relevant domains such as IT, Finance, and Marketing. However, the task of manually classifying these varied job titles is incredibly laborious and inefficient.
Machine learning approach to tag job title names
This is where machine learning techniques prove invaluable. Rather than manually categorizing each job title, I first conducted a manual classification on a subset of the 3,000 titles to create a training dataset. Using this dataset, I developed a classification model that predicts the most appropriate job title category for each entry. This approach significantly reduces the time and effort required for reviewing and correcting job titles.
In the following sections, I will share some practical code snippets to demonstrate how this can be implemented.
Preparing data set
First up, we need to create our training dataset. This involves pairing each job title with its corresponding tag. Below is an example code snippet that demonstrates how to read a CSV file and split it into training and testing sets.
file_dir="C:/Users/takes/Workforce/CDO/data/CareerPath"out_dir = "C:/Users/takes/Workforce/CDO/data/CareerPath" file = "job_title_training dummy.csv" df = pd.read_csv(file_dir + "/" + file , encoding="cp932")display(df)
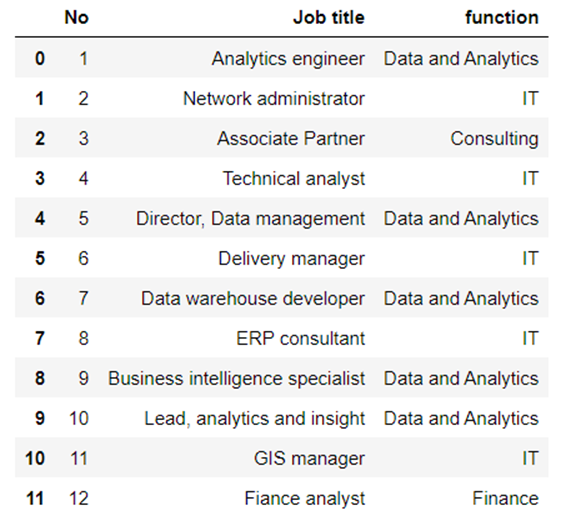
import sklearn.model_selection train, test = sklearn.model_selection.train_test_split(df, test_size=0.2,random_state=42)
Converting Job Title texts into a vector
Next, we need to transform these job titles from plain text into a format that a machine learning algorithm can work with. This involves converting the unstructured text data into numerical data, a process known as 'Vectorization'.
Vectorization is a standard technique in Natural Language Processing (NLP). Essentially, it represents multi-dimensional data numerically. Each job title is treated as a 'Document', and each document is converted into a vector that counts the occurrences of each word. In NLP terms, this is called a 'Document-Term Matrix'.
| Analytics | Engineer | Director | Data | Management | Lead | Insight | |
| Analytics Engineer | 1 | 1 | |||||
| Director, Data Management | 1 | 1 | 1 | ||||
| Lead, analytics and insight | 1 | 1 | 1 |
TF-IDF conversion
While our initial Document-Term Matrix does a decent job representing each job title, we can refine it further. A classic method to enhance this representation is by calculating the relative importance of each word within a document.
TF-IDF, or Term Frequency-Inverse Document Frequency, measures the importance of a word by considering how often it appears in a document while discounting it if it appears frequently across many documents. This helps in highlighting unique words that are more indicative of a specific job title. Instead of diving into the mathematical details, let’s see how it works in practice with our job title list.
How to Write the Python Code
Implementing this in Python is straightforward thanks to the scikit-learn (sklearn) library. Here's a simple way to convert your training set into a TF-IDF vector:
- Use the CountVectorizer object to tokenize each job title into words.
- The fit_transform method of CountVectorizer will count the occurrences of each word, such as 'Analytics'.
- Then, create a TfidfTransformer object and apply it to the count vector.
Here’s a code snippet to illustrate this process:
count_vect = CountVectorizer()title_counts = count_vect.fit_transform(train['Job title'])title_counts.shape tfidf_transformer = TfidfTransformer()title_tfidf = tfidf_transformer.fit_transform(title_counts)title_tfidf.shape
This will give you a TF-IDF vector that better represents the unique characteristics of each job title.
Training model – Naïve Bayes Classifier
Now it’s time to train our predictive model. In this article, we'll compare the performance of two models available in scikit-learn.
First up is the Naïve Bayes Classifier. This is one of the simplest classification algorithms, based on Bayes’ theorem. Rather than diving into the theory, let's jump straight into the implementation.
Using the MultinomialNB class, we can create a Naïve Bayes classifier by feeding it the TF-IDF vector of job titles and their corresponding job function names. Once the classifier is built, you can use it to predict the classification of job titles in the testing dataset. Here’s a sample code snippet for making predictions:
clf = MultinomialNB().fit(title_tfidf, train['function'])
title_test = test['Job title']func_test = test['function']
test_counts = count_vect.transform(title_test)test_tfidf = tfidf_transformer.transform(test_counts)predicted = clf.predict(test_tfidf)
testc = len(test)true_c = 0for title, func_pred, func_act in zip(title_test, predicted, func_test): print(f' {title}, {func_act} => {func_pred}') if func_pred == func_act: true_c = true_c + 1
print(f'Accuracy of Naive Bayes1={true_c/testc}')The print function outputs both the expected and actual predictions for the test data. In this example, the first three cases are correctly predicted, but the prediction for the fourth row is incorrect. Overall, we achieve an accuracy of 75%.

Training model – Support Vector Machine
Next, let’s train another model: the Support Vector Machine (SVM). SVMs are particularly effective for high-dimensional data like TF-IDF vectors.
Implementing SVM in scikit-learn is straightforward. Using the same training and testing datasets, the SVM model achieved perfect predictions. Here’s the code snippet:
svm_clf = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('clf', SGDClassifier(loss='hinge', penalty='l2', alpha=1e-3, random_state=42,
max_iter=5, tol=None)), ])
svm_clf.fit(train['Job title'], train['function'])
predicted = svm_clf.predict(test['Job title'])
acc = np.mean(predicted == test['function'])
print(f'Accuracy of SVM {acc}')Conclusion
Machine learning is a powerful tool for business analytics professionals. In the realm of workforce data analysis, text classification models provide us with valuable options to make sense of unstructured data related to people and their roles. This approach not only saves time but also enhances the accuracy and efficiency of data analysis.